{kind=link}
🔗 Node Operators MUST have a process to enable emergency rollback of upgrades
Copyright© 2026, Lido Labs Foundation. This document may be used, modified, copied and distributed under the terms of the Apache 2 License.
This specification defines risks that can apply when operating a blockchain node.
It describes mitigations that can minimize the likelihood that particular risks will be realized and cause a problem, such as compromising the ability to manage a node or actions that result in reduced economic rewards, or penalties such as slashing.
Finally, it provides a set of controls to verify that a Node Operator is appropriately managing the relevant risks.
This specification builds on the DUCK knowledge base [DUCK]. The risk framework and explanation of mitigation strategies have been updated, based on feedback from practitioners. A specific set of controls has been added; statements of requirement that can be tested, to ensure that as far as possible a Node Operator is following the recognized best practices to minimize risk and effectively maximize their returns.
While other standards such as AICPA's SOC 2® [SOC2] or ISO's 27001 standard [ISO27001] can be applied to Node Operators, they often include more general requirements than this specification, reflecting a broader scope.
The relevant controls from several such standards are explicitly linked to the controls in this specification. The purpose of this is twofold: to simplify the process of certifying conformance to this specification for Operators who have already undergone testing against those standards, and to simplify the process of assessing Node Operators who have been certified as conforming to this specification against those specifications.
As well as sections marked as non-normative, all authoring guidelines, diagrams, examples, and notes in this specification are non-normative. Everything else in this specification is normative.
The key words MUST, MUST NOT, and SHOULD in this document are to be interpreted as described in BCP 14 [RFC2119] [RFC8174] when, and only when, they appear in all capitals, as shown here.
Conformance to this specification is based on meeting the requirements expressed in the Controls Catalog.
This specification divides risk into eight categories for Node Operators to consider in ensuring the quality of their overall setup.
Where applicable, risk identifiers correspond to those that were introduced in [DUCK], and will remain stable. This may mean that some identifiers are retired and will not be re-used.
These are risks explicitly arising from management of financial and regulatory compliance processes. (Many other risk categories have a direct financial impact).
| ID | Risk Group | Risk Vectors | Risk Vector Description | Relevant Mitigations |
|---|---|---|---|---|
| FIN1 | Process | Onboarding | Onboarded entities are not adequately vetted to ensure financial, operational, regulatory, or reputational appropriateness, resulting in potential financial, legal, or reputational damage |
|
| FIN2 | Infrastructure | Deposit | Fiat and digital assets deposited are not received in the appropriate currency, address, or fiat account, leading to financial loss | |
| FIN3 | Infrastructure | Deposit | Fiat and digital assets are not correctly processed and assets are misallocated to individuals, entities, or operational addresses leading to financial loss | |
| FIN4 | Process | Withdrawal | Fiat and digital assets are not correctly disbursed to individuals, entities, or addresses, leading to financial and reputational loss | |
| FIN5 | Infrastructure | Compounding | Staking rewards are not appropriately collected, governed, restaked, compounded, or allocated to clients leading to financial loss | |
| FIN6 | Process | Reporting | Financial reporting requirements are not adhered to or inconsistently applied, leading to regulatory, legal, and financial consequences |
|
| FIN7 | Process | Up to date compliance | Failure to review relevant regulation and update compliance procedures leading to financial, legal, and regulatory repercussions |
These risks arise from performing slashable actions, that lead to penalties. Note that frequent slashing penalties are likely to incur a reputational risk.
These risks are due to connectivity issues. Depending on the network these can lead to reduced rewards, in effect an opportunity cost, or to more direct financial penalties.
The risks associated with key custody cover all private keys and key material. However in some cases the way a risk manifests or impacts depends on the type of key. For example:
Many risks arise through vulnerability to hacking, whether carried out by a malicious external actor, or facilitated by a current or former member of the operational team.
Risks related to process errors, inefficiencies, and weak general infrastructure.
Risk related to partners and specific third-party services.
| ID | Risk Group | Risk Vectors | Risk Vector Description | Relevant Mitigations |
|---|---|---|---|---|
| SPS0 | Counterparty | General Counterparty Risk | Whenever a service is provided by a third party, the relevant risks are run by the third party, but in most cases at least some and often the bulk of the consequences for a failure will be borne by the node operator. |
|
| SPS1 | Process | Exit Risk - Delinquent state |
|
Risks that impact the reputation of a Node Operator, likely to lead potential and actual customers to choose a different partner to work with.
This Mitigation Strategies section serves as a go-to resource for node operators, providing actionable insights and mitigation options to enhance the security, reliability, and efficiency of their operations.
Most of the best practices that optimize up-time, access control and general stability directly apply to operating a node properly. However, for some risks specific to running a node operator, high levels of process segregation need to be achieved for mitigation to be effective.
A core principle for mitigating risks is to actively identify and manage the risks. This means understanding the particular risks, the likelihood of something going wrong, and the likely impact if that does occur. That information enables a Node Operator to decide what level of risk is reasonable and how to prioritise available resources to mitigate risk.
Risk management decisions need to take into account any regulation that obliges a Node Operator to meet specific benchmarks or implement specific mitigation strategies or other activities.
A first step for effective risk management is to document the potential risks, as well as the tools and processes currently in place to address those risks.
Documentation needs to include an assessment of the relevant risks, an explanation of what level of risk is acceptable and why, and how each process or infrastructure component contributes to and protects against risks.
This enables Node Operators to identify activities that are not contributing to the business, or that actually increase the potential risks they face. The accuracy, availability and completeness of this information is of crucial import.
A common industry approach to assessing risks is to consider the probability of an event occurring and the likely impact of that event.
If these are ranked on a linear numerical scale (e.g. probability between 0 and 1), and an approximate overall financial impact, they can be multiplied, provide a simple initial ranking for priority of mitigating each risk.
Since the cost of risk mitigation varies considerably, the overall priority for addressing risk, or deciding that a given level of risk is acceptable, generally depends on comparing the risk ranking with the cost of mitigation, and available resources.
There are a number of factors to take into account when assessing the overall financial impact of a given risk, with the direct cost incurred as the most obvious. It is important to understand the time required to mitigate the impact of an event, and the cost that will be incurred over that time.
An incident can incur a variety of costs in terms of employee time spent managing the incident, communication, and follow-up, new mitigations implemented to mitigate concrete or reputational damage such as replacement or additional infrastructure, as well as potential costs of compensation or legal costs.
It is also useful to consider opportunity costs such as competitors taking advantage of an incident to promote themselves as a better alternative.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Predicting the likelihood of an unexpected future event is generally difficult, and results are unlikely to precisely match the predictions. Nevertheless it is important to consider the context of a specific operation and attempt useful predictions.
Unless a validator system is immutable and fully automated, there will be people involved in managing it. It is therefore important that appropriate management of people is part of managing the validator node. This impacts in various areas, from mitigating the risk of hacking by unknown parties with access to privileged roles, to the ability to provide timely incident response and minimize the damage caused by a security incident.
As well as the Controls for People Management some relevant controls are grouped with other areas, such as
It is important to identify individuals who have access to and can control aspects of the operations of the Validator node. While a globalized workforce can provide multiple benefits, it is difficult to hold an anonymous individual accountable. This fact is repeatedly used by large-scale hacking operations to infiltrate valuable targets with a goal of eventually using access granted willingly to rob, damage, or destroy the target.
It is important that individuals whose actions influence the Validator node have appropriate skills, and as the ecosystem evolves training helps maintain a relevant skillset.
As well as themes specific to the individuals' tasks and Node Operator internal policies (such as this document), there are a number of areas where up-to-date skills matter, such as:
In a nutshell: technology needs to serve the business goal, not the other way around.
To ensure this happens, it is important to consider both the business goals and the available technology, and then use appropriate technology to meet those goals.
Updates to software components provided by third-parties often address newly-discovered or longstanding vulnerabilities. It is a best practice to update software regularly, but it is important to check for vulnerabilities that can be introduced by an upgrade as part of a supply-chain attack, and to verify that any customization of open-source software, or specific configuration options, as well as other software used by the node operator, are all compatible with an update and do not create new vulnerabilities on updating.
To avoid double signing, validators can maintain a history of messages they signed. This data is crucial, as inconsistencies can cause a double-signing event. The data needs to be reliably persistent, and properly connected to the systems that use it.
A common format for anti-slashing data is defined by Slashing Protection Interchange Format.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Tools that manage signatures for transactions generally provide a workflow that includes passive and active protection against a variety of risks. Using these tools helps minimize the chances that a signature is given without checking what is being signed, and that risk-bearing transactions require appropriate authorization.
Properly configured signature management tools also provide the ability to recover, or mitigate any problems, in the case where a transaction was not completed.
As well as the use of various kind of "multi-sig", which can include simple requirements for multiple signatures, or incorporate such techniques as multi-part compute ("MPC") or the like, signature management tools can include automated verification steps in the process of authorizing a transaction.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
A diverse set of clients for different protocols can reduce "blast radius" in a case where one client has a protocol error or other bug. This can be especially important if the bug causes a chain split. A common scenario is when an upgrade introduces a problem. The ability to migrate relevant keys to a different client, if a specific client error is observed, provides an important layer of protection. In addition, maintaining client diversity helps ensure that the network as a whole does so, ideally providing real protection against a vulnerability present in a single version of a single client by ensuring that particular version does not dominate the network.
Note that there are often a different range of clients available at different levels of the infrastructure. For example in Ethereum, it is possible to run different clients on each of the Execution and Consensus layers.
Node operators need to withdraw validators correctly, as they can otherwise be put into a delinquent state. This can result in direct penalties, or an opportunity cost realized as monetary losses.
Information management can mitigate many risks. One aspect is the management of highly confidential information, such as the management of signing keys or withdrawal keys, but it is also important to manage operational information.
Best practice for credential management is to use a Single Sign on system, that gives users authorized access to secrets through e.g. certificates, and/or vault mechanisms.
In this way, everything is audited, and anomaly detection can be activated for those vaults.
Using multi-sig wallets requiring authorization from multiple parties for specific actions, helps to ensure both that relevant access is monitored and that it is correctly controlled.
Many different components interplay while a staking operation is going on. If confidential information is not protected by encryption, it can be intercepted and read during transmission. There is also a risk of accidental or malicious leaking of stored information, which can be somewhat mitigated if that information is stored in encrypted form.
It is therefore crucial to ensure that confidential data is only stored and transmitted in an encrypted state.
Cold Storage, in particular "air-gapped" storage, can help protect information not used often such as withdrawal keys, private key generation materials, and the like, by making it more difficult for malicious entities to access the information and by reducing the chance that it will be leaked in the event of accidentally publishing data.
Operating a node normally entails the use of a range of keys, such as
It is important to protect private keys from accidental or malicious misuse, and in particular unplanned deletion. It is not normal to provide broad access to unencrypted signing keys.
Modern vault systems enable the enforcement of policies to ensure that access to keys is only available with verified roles, and deletion is managed according to established protocols.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Node operators are likely to rely on a wide range of operational information, including internal procedures, understanding software configurations, plans for future development, and employee management.
Best practice includes ensuring there is no single point of failure due to centralized information being held by a single external provider or only being known to a single employee.
Documentation, even if rarely actively read by those responsible for operations (who presumably know their job), is important for many reasons including
Loss of important information, especially loss of control over keys, can have a crippling impact. It is important to have mechanisms to protect against, and recover from, unintentional or malicious deletion of important data.
Best practice includes having journaled backups of important information.
Access Control covers physical access to devices and facilities, the ability to connect to servers through networks, and the ability to perform specific tasks, such as getting answers to requests.
The core principle to follow in granting authorization is Least Privilege. This is generally achieved by using some form of Role-Based Access Control, in combination with an inventory of assets and services, to ensure that only those who need access are granted that access, and that it is revoked as soon as appropriate.
Tracking this information is important to ensure that access can be audited and verified.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
The core of Least Privilege is that access is only granted to those who need it, and only for as long as it is relevant. This means that an individual user's privileges are likely to change over time, and in particular any offboarding process includes a rapid revocation of user's assigned roles.
Almost all Least Privilege implementation is managed through Role-based Access Control (commonly known as "RBAC"), where a set of roles are defined according to the tasks they need to perform, and access rights are based on holding a particular role, with individual users assigned relevant roles that are revoked or deliberately renewed on a timely basis. It is important to ensure that individuals can fulfil their designated tasks, without having authorizations they do not need.
docker exec -uroot, or impersonation in Keycloak)The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Following the principles of defense in depth and least privilege, it is important that nodes are not directly accessible without permission, and that they do not leak information to the Web that can help malicious parties gain unauthorized access.
Best practice is to use password and related authentication policies to ensure that access control mechanisms are sufficiently strong at every layer of the infrastructure. This can include appropriate requirements for the strength of passwords and the use of Multi-Factor Authentication as well as Multi-Sig requirements.
Physical devices are subject to physical changes, including environmental issues such as temperature extremes that can cause damage, and utility failures such as power or internet failure.
This covers all physical devices that can access the Node, as well as all areas in which such devices are kept, whether "on-premises", distributed, hosted by a third party, or remote mobile devices such as laptops.
Best practice for managing physical access includes ensuring that authorization is only granted as necessary, following the principles of Least Privilege. Generally this means some devices are physically segregated in areas where access is restricted according to function. Note that this covers the use of devices authorized to access the networks that nodes operate on, and is particularly important for devices authorized to access management and analytical functions of nodes.
Ideally all physical access to premises and facilities is monitored, to deter and determine whether the facility is subject to piggybacking. This term refers to the situation where an unauthorized entrant is allowed in by someone who has a valid authorization for themselves. In the context of remote operators' access through a computer, controlling this is particularly challenging in practice.
Piggybacking can occur inadvertently through politely holding a door for someone without checking that they have current valid authorization to enter, negligently by allowing someone to enter for a legitimate purpose despite knowing that person does not have valid authorization, or maliciously allowing someone to enter knowing that their purpose is nefarious.
In the inadvertent case, relevant mitigations include
To minimize negligently allowed access, it is important to ensure that access systems are effectively maintained and managed to ensure there is no good reason to allow an unauthorized person access. This can range from the design of onboarding systems to the effectiveness of internal management feedback systems for discovering unanticipated problems faced by operators.
Best practice includes managing physical access with systems that can efficiently enable access to authorized parties (keycards, biometric scanners), and monitor actual access such as visual verification that the authorized party is the one entering.
It is important to log and audit access sufficiently frequently to detect problems - see also Monitoring.
A single validator represents a single point of failure, that can introduce slashing or downtime risks.
[DVT] (Distributed Validator Technology) provides an approach to mitigating this problem, by distributing the keys and the hardware that runs validation, in such a way that multiple clients physically located in different places share the task of validation. Thus if a single client or small number of them fail, the overall validation is unaffected. (Note that while the Ethereum Foundation provides a specific technical specification for DVT that has been implemented the principes can be implemented in different ways.)
Likewise, maintaining multiple validators running on separate hardware and software can increase resilience to a failure in any one platform.
To ensure that a local utility failure does not impact a validator, it is useful to have redundant systems, such as a backup power supply e.g. through local batteries or power generation, and for connectivity e.g. physical connection such as fibre-optic cable, and one or more modes of wireless connection.
The level of mitigation that is appropriate depends on the level of risk, and the costs of both failure and mitigating failure. These calculations mean economies of scale often enable larger-scale operations to be more robust than smaller ones, for a given price.
It is also important to ensure that facilities have appropriate protection from relevant environmental risks such as fire, flooding, extreme wind, as well as earthquakes and destructive physical attacks. Appropriate mitigations will depend in part on the specific location and nature of the facility, but will generally revolve around siting of facilities, their architecture, and specific measures to ensure resilience.
Monitoring can also identify specific conditions that adversely affect equipment and suggest that a lifecycle plan needs adjustment - whether writing off equipment destroyed by fire, or increasing preventive maintenance for physical access systems that are being used far in excess of expectations that drove the existing maintenance plan.
The lifecycle of equipment, most particularly node servers and computers used to access and manage them, is a determinant of overall security.
Monitoring can also identify specific conditions that adversely affect equipment and suggest that a lifecycle plan needs adjustment - whether writing off equipment destroyed by fire, or increasing preventive maintenance for physical access systems that are being used far in excess of expectations that drove the existing maintenance plan.
A secure development lifecycle helps ensure that vulnerabilities are not introduced to codebases, and subsequently deployed.
A comprehensive test suite helps ensure changes do not introduce new vulnerabilities or situations that lead to operational failures. Equally, it is important that someone other than the developer who produces Code changes reviews them.
Static and Dynamic analysis is important, as well as user testing wherever changes impact user interface or user-generated content.
Measuring test coverage, and requiring new tests that are reviewed as part of and code review, help ensure that coverage is sufficiently comprehensive to detect errors that can arise through later changes.
Unchecked inputs are a major vector for a range of attacks. These include
Ideally, the load balancer in front of the node filters out all traffic with payloads that cause overflow. Additionally, it is important to validate inputs against the relevant parameters, particularly where these allow a range of functionalities to be triggered.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Updating software is a major risk vector. Good processes for software development and managing the deployment of updates are important to mitigate some of this risk. As well as having control over the update process, it is important to have the capacity to revert to a known environment in an emergency where an update has been found to introduce unexpected problems.
Validator software, and other software validators use, is very often open source. However, customizing software can introduce errors. In addition customizations can produce incompatibilities when software is updated.
This means that any customization introduces a need for continued extra testing, in particular whenever relevant software is updated. Customization also increases the risk that test coverage is inadequate, meaning a future error will not be found in pre-deployment testing and only discovered through a failure operating in production, with attendant risks of reputational damage, direct losses, and increased cost for incident management.
It is important to manage the configuration of hardware, and software. A minimal profile helps reduce possible attack surface, while minimizing, and carefully tracking, customization is important to ensure smooth and safe upgrades.
Software configuration to follow includes, among others:
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Protection against malware needs to be implemented on all assets and users need to exercise proper caution.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Use separate tests and staging environments
This minimizes a potential blast radius. It is important to run any change (even an update of a validator software or Web3Signer) through a test environment first to maximize the likelihood that any errors can be discovered before they impact a production environment.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Containerized and orchestrated environments are designed to reinforce security by automating many good practices, with mechanisms that have been widely tested in diverse environments. As tools that can be used well or badly, their best practice recommendations are important to ensure the full benefits are realized.
Human error is always a risk. An automated script, whether or not invoked by a human, can help minimize inadvertent errors.
Another benefit of properly set up automation is that it can help reduce the risk of exposing secrets.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Monitoring is an important tool to identify risks and gain relevant data, and some requirement for it is a very common feature of compliance and security frameworks.
Monitoring takes many forms. It can be done internally, and provided as a service. The latter is especially common for monitoring the health of widely available third-party infrastructure such as blockchains, and cloud services.
Monitoring can take place throughout the ecosystem. Low-level indicators such as whether network traffic is within expected or design parameters, whether databases are being updated at expected rates, or whether server facilities are maintaining an appropriate temperature are all examples of monitoring with fairly obvious value, and where immediate remediations or further investigation is straightforward.
Monitoring access to physical infrastructure is more complex, and the resulting information about people is subject to privacy requirements, but can be a useful diagnostic tool if something goes very wrong, or if you just want to know who keeps blocking the server-room door open on warm days.
As well as monitoring in real time, logging information allows analysis to discover information that is only observable though variations (or non-variations) in specific monitored information over time.
Given the importance of logged information, and of privacy requirements, best practice is to have a clearly documented policy for record retention. This needs to retain enough information to enable historical analysis and comparison. Some data are best only retained in anonymized form, or stored with extra security provisions applied.
A good monitoring system provides very broad coverage, with redundancy both as an aspect that can be monitored to detect anomalies and to eliminate the risk of a single point of failure - when monitoring is compromised it can indicate a simple failure of the monitoring system, but can also mask a broader issue that the system is expected to detect.
With a good monitoring system in place providing broad coverage of operations, there needs to be useful and targeted alerting system based on the monitoring system.
To learn that a potential problem has been identified, as soon as possible, and act on it effectively, a monitoring system needs a robust targeted alerting system. A system that overloads its watchers with alerts is likely to lead to alert fatigue, where the alerts are ignored in practice because too often they require an onerous human response when they are not identifying a real problem. Like monitoring systems in general, redundancy in alert systems is important.
Knowing an incident has occurred can trigger an Incident Response Plan, but if it relies on individuals, it is important to provide 24/7 response. Many attacks are deliberately targeted for times when responders are less likely to have high availability.
Alert systems can in turn drive automated emergency responses, ranging from capture of increased levels of detail, through requesting additional authorization beyond the normal requirements, to full system shutdowns.
Here again, there are important trade-offs between ensuring a highly responsive system, and one that is robust in the face of real-world variability. For example, a system that can automatically suspend multi-sig transactions unless they are authorized within a short time is not always appropriate, because it can interfere with normal operations over a high-latency network or where a number of individuals are expected to coordinate extensively, taking a significant amount of time, before authorizing a particular action.
Among many aspects of Validator Operations to monitor directly are the following:
Monitoring for unusual patterns or spikes can help detect a security breach or an exploit in progress. In many cases, even if security is breached, secure and accurate logs are important to determine how this took place, in order to protect against recurrence. The following are among indicators of a security issue, and information that can help determine what happened.
If two validators with the same identifiers are running at the same time is important to shut one down as fast as possible. Most validators provide built-in mechanisms to detect doppelgangers. Other tools and technicques can also detect and act on this.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
ssv.networkThe following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
Communication is important both during normal operations, and when an exceptional security incident occurs that could adversely affect the normal operations, or the users of a system.
There are therefore two core parts to a Nore Operator's communication strategy:
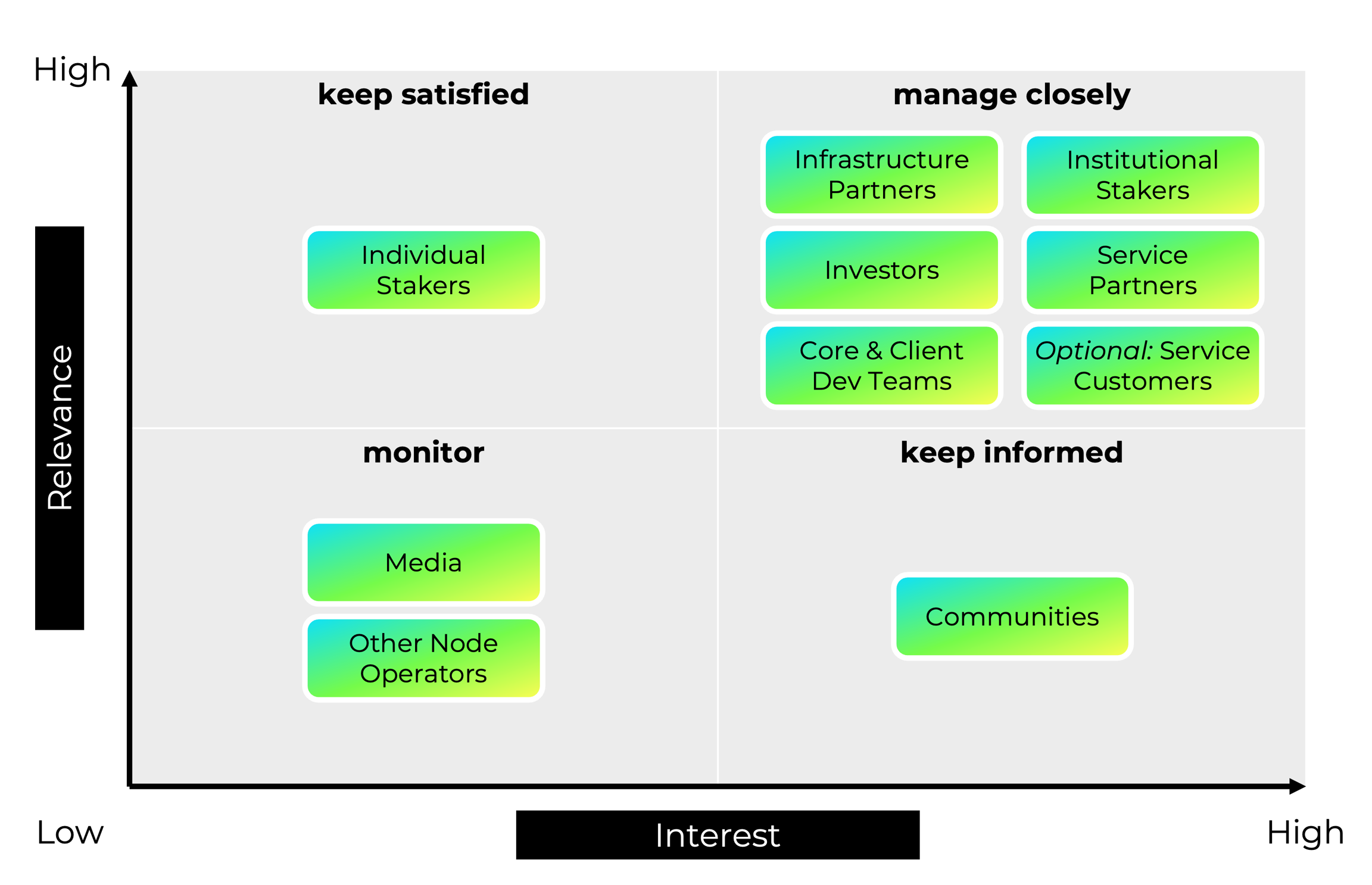
Developing appropriate communication procedures relies on understanding both the communications channels an organization has or can have, and its stakeholders. The goal is to ensure those stakeholders have timely access to relevant information in a useful format.
Some key stakeholders are Anonymous Stakeholders, who might follow a Node Operator's public information channels, or operate independently, but who do not provide individual communication information to Operators.
Regulators of various kinds can require that Node Operators provide them with specific information, but do not necessarily communicate with Node Operators on an individual basis
Node operators will also have Known Stakeholders, who have an identity known to the Node Operator that includes at least one direct communications channel such as messaging, email, or telephone. These typically include at least some of
Stakeholders' preferences for communication channels differ. While many Known Stakeholders will have explicitly requested direct communication, it is important to have additional channels that enable Anonymous Stakeholders to follow important developments.
Broadly, communication channels can be considered two-way, enabling communication with an individual Known Stakeholder or with all of them at once, or broadcast, enabling Anonymous Stakeholders to receive important information, often while preserving their anonymity.
Additionally, some mechanisms allow for persistent information, while others are only temporary; A website can be maintained long-term or the information can be removed, information sent by email can easily be retained by the recipient in perpetuity, while information in e.g. a Slack or Telegram channel could be deleted after a matter of days or weeks
It is also important, especially for services used for two-way communication with Known Stakeholders, to consider the security and privacy of the channels used. While channels such as Telegram or Whatsapp use encryption, in the case of the former all communication is decoded at some unknown centralized point, in the latter large amounts of metadata are available to the service provider.
While many messaging services can behave in either manner, some such as websites are well-suited to broadcast communication and others are more suited to individual two-way communication.
As well as identifying the most appropriate channels for communication with Known Stakeholders or classes of Anonymous Stakeholders, it is important to understand what it is appropriate to communicate, and to whom. Some stakeholders will expect a "close management", with direct individualized two-way communication, and very rapid reporting on incidents and important information. Others will want to know that they are informed in case of security incidents, or important regulatory changes, but prefer a lower volume of information. It is likely that different circumstances will mean that a given Stakeholder moves between "categories", with different communications strategies or procedures being more appropriate depending on specific context.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
A number of jurisdictions (such as the EU, with the [GDPR]) regulate the use of information about individuals, and it is important to understand and comply with such regulations to avoid reputational, legal and financial risks.
An Incident Response Plan documents procedures for managing security incidents and events, as guidance for employees or incident responders who believe they have discovered, or are responding to, a security incident. A well-documented Incident Response Plan helps employees in a high-stress situation by providing a reminder of all important actions and considerations. To be useful, it is necessary that relevant employees know the plans exist, and how to find them.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
There are several ways to identify that a security incident is taking place. Best practice is to have extensive monitoring in place, to identify anomalies early, with alerting and potentially direct reaction mechanisms. Although learning from third-party discussions is a terrible way to find out about an incident, it is still better than simply not discovering it, so monitoring channels where such discussions take place is a valuable part of an overall strategy.
This is often referred to as a "Post Mortem", used to learn from the event and improve relevant Incident Response Plans.
A Disaster Recovery Plan is a specialized Incident Response Plan that gives guidance on recovering one or more information systems at an alternate facility, in response to a major hardware or software failure including the partial or complete destruction of facilities.
The following list is an uncurated selection, alphabetically sorted, and not a specific recommendation
These are also known as "Pre-Mortems".
Regular simulations of implementing an Incident Response Plan ensure that relevant personnel are familiar with them and can efficiently follow them when necessary. "Pre-Mortems" simulating or "war-gaming" a specific failure also tests those procedures to give some idea of whether they are appropriate and adequate. It also often motivates participants to think about other risks, and whether appropriate procedures and mitigations are in place.
There are many possible approaches to an incident simulation, and many eventualities that they can cover. Example topics for Pre-Mortems include variations on themes such as
Articles such as How to Use Pre-mortems to Prevent Problems, Blunders, and Disasters offer further information on how to plan and implement simulations, and how to derive the maximum benefit from them.
As well as direct financial losses, security incidents can also result in substantial reputational damage. Appropriate Incident Communication with stakeholders about security incidents, both during and after the relevant incident, can significantly mitigate this risk.
It is important to note that inappropriate communication during an incident can increase the damage. External communication has to balance stakeholders' need for information that enables them to respond in a well-informed manner against the importance of providing clear information with as much certainty as feasible that it will not later be contradicted.
This section contains controls that are material to Node Operator risks. Some of these control criteria correspond to similar controls from three common frameworks:
Where relevant, corresponding controls from those frameworks are identified and linked from ValOS controls.
🔗 Node Operators MUST document how their processes and tools serve their business goals
🔗 Node Operators MUST review their dependencies on staff and external suppliers and how to replace key staff or suppliers every year
External suppliers can change terms, shut down products or support, and key staff can leave or be indisposed for long enough to impact business functions.
🔗 Node Operators MUST document their assessments of risks, and what risks they class as acceptable
🔗 Node Operators MUST ensure that processes for risk mitigation are followed in practice
Best practice is to ensure that where possible, processes are automated
🔗 Node Operators MUST document payment processes including currency and exchange details
🔗 Node Operators MUST review relevant regulation and update processes for compliance as necessary at least quarterly
🔗 Node Operators MUST know the identity of entities who are authorized to manage operations
Best practice is to identify every individual who works for the Node Operator. In the case of corporate third-party providers, sensible due diligence does not always extend to identifying specific individuals.
🔗 Node Operators MUST implement documented procedures for evaluating and reviewing counterparty risks from vendors and partners
🔗 Node Operators MUST ensure entities who are authorized to manage operations have and maintain the necessary knowledge to minimize risks to the Node Operator in the course of performing their work
🔗 Node Operators MUST keep third-party software up to date
This control does not imply that the latest available update is automatically applied, rather that Node Operators have clear and effective mechanisms to ensure they are aware of updates and apply them in accordance with their update management procedures, taking into account the controls in Controls for Development and Update Process.
Best practice is to monitor software in use, to know when an update is available, and to update as fast as possible while following procedures to manage those updates securely. In some cases, assessing an update will lead to a decision that there is no need to apply a specific update, or a risk in doing so that outweighs the benefits.
🔗 Node Operators MUST have a persistent local anti-slashing database
🔗 Node Operators MUST document signature requirements for high-value transactions, including the definitions used to identify such transactions
🔗 Node Operators SHOULD use signature management tools to help secure high-value transactions
🔗 The primary and backup/failover versions of Signature management tools MUST implement mechanisms to ensure data continuity
🔗 Node Operators MUST deploy at least 2 distinct client applications for any level of the blockchain where at least 3 clients are available
🔗 Devices that control critical functions MUST be dedicated to that purpose, and configured with only the necessary software for their intended purpose
This applies to servers acting as validators, but also to devices authorized to access and administer those servers remotely.
🔗 Node Operators MUST implement processes to withdraw validators from a network in such a way that they are not penalised for disappearing
🔗 Node Operators MUST document configuration of software and hardware
🔗 Node Operators MUST implement appropriate key management procedures
Best practice includes following a commonly recognized key management standard such as
🔗 Node Operators MUST document and follow information lifecycle processes for important operational information
This includes the definition and enforcement of retention periods, and the use of thorough deletion mechanisms, such as shred.
🔗 Node Operators MUST implement backup procedures, at minimum daily, for important operational data
🔗 Backup Procedures SHOULD produce journaled backups covering relevant retention periods
🔗 Node Operators MUST implement protection against accidental or malicious deletion of data
These requirements cover all information required by controls in this specification.
🔗 Node Operators MUST record and maintain important operational information
Best practice is to use a documentation management system. While this is likely to have different levels of access control, it is important that no information is available to only one employee.
🔗 Node Operators MUST have a policy for data retention
This needs to provide adequate retention to enable historical analysis and checking for anomalous patterns, while minimizing stored data and ensuring compliance with relevant data protection regulation.
🔗 All services MUST require appropriate authentication privileges
For example, a Node does not respond to anonymous requests from an unknown user.
🔗 Networks MUST be segmented, to restrict access to systems that are identified as needing it
🔗 Nodes MUST NOT respond to requests from outside a defined network, except those that are explicitly defined as necessary
Fulfilling this requirement means maintaining a whitelist of individual services that are authorized to respond to requests from broader networks.
🔗 Entry to physical server locations MUST require authorization
For example, a biometric scan or the use of a keycard.
🔗 Software MUST NOT run with, and a user MUST NOT have a higher level of privilege than necessary
For example, check that software does not run as root, that users do not log in directly with root privileges, and software and users are granted fine-grained access based on need rather than broad-based access for simplicity.
🔗 A review of Access Rights MUST take place regularly
This covers both the processes and tools for granting and revoking access rights, and verifying that they are effectively managing access rights according to the relevant principles (Least Privilege, Role-based Access Control. Best practice for this review includes:
🔗 All data in transit MUST be encrypted, 🔗 and SHOULD use the most direct transmission available
🔗 All data "at rest" MUST be stored in encrypted form
This covers all services that communicate data, such as Databases, Web servers, Load balancers, Authentication systems, CI/CD pipeline tools, etc.
Best practices include ensuring that the latest version of TLS is being used, with secure algorithms.
Current best practice includes assessing the cost and risk associated with moving to quantum-safe cryptography, and appropriate timelines.
🔗 Node Operators MUST log network traffic, and analyze the logs for anomalous behavior
🔗 Any operation that requires privileged access MUST be logged
🔗 Any assignment of a key, or assignment of a role to or removal of a role from a particular key, MUST be logged
This includes monitoring software that has privileged access.
🔗 Every change in the status of people who have access to any function of the Node, or physical access to any hardware, MUST be logged
🔗 Any event that results in slashing MUST be logged
🔗 Logs MUST provide a sufficiently detailed view of hardware and network performance to enable upgrade needs to be forecast, and to alert if validators are operating with excess latency
Tools such as Zabbix can also display a live feed of CPU and memory usage of each compute instance.
🔗 Node Operators SHOULD have processes in place to manage environmental threats
This includes monitoring for such threats and physically hardened facilities (e.g. fire- and flood-resistant server rooms), and physically decentralized infrastructure. It can also incorporate the use of DVT or related approaches to managing physical decentralization.
🔗 Node Operators SHOULD implement failover validators in different physical locations
🔗 Node Operators SHOULD have processes in place to manage equipment lifecycles
This includes monitoring performance and performing preventive maintenance, upgrades, or replacing equipment as appropriate, as well as processes that ensure equipment is correctly retired including removing data and any hardware-based authorization.
🔗 Code development MUST follow secure development processes to avoid introducing security risks
This is a broad area. A few specific controls are included in this specification, but this requirement is intended to ensure a general production philosophy.
🔗 Node Operators MUST document procedures for updates to code
🔗 Source code MUST be managed in a repository
🔗 All changes to deployed production code MUST be tested and reviewed before deployment
This covers all changes to code, including when it is necessary to roll back an upgrade.
🔗 Updates to third-party software MUST be checked for vulnerabilities before deployment
This covers verifying that all software updates, including validator and other node clients as well as specifically written custom code or updates, have been audited to ensure they are not introducing known or new vulnerabilities.
Best practice is to perform both internal and independent external audit, and to ensure the identity of the coders is known. Likewise, in best practice third-party code developers are only given access to code they need to do their work, are held to high standards of confidentiality, and work with a well-defined set of expectations.
🔗 Software update procedures MUST include an assessment and application of configuration settings
🔗 Code MUST verify that input is safe before operating on it
🔗 Code MUST NOT produce invalid outputs
🔗 Components SHOULD use Cross-Origin Resource Sharing and Content Security Policy Level 3 to protect against Server Side Request Forgery
These requirements ensure that data passed between software components can be handled safely by the receiving component. It includes data entered manually by users.
🔗 Node Operators MUST have thorough test coverage of their software and operating procedures
There is no magic percentage figure, but ideally unit tests and integration tests cover every functionality and interaction managed by code the Node Operator uses, whether self-managed or provided by a third party.
🔗 Updates MUST include an audit of all code and user interactions they impact
This means testing not just the new code deployed, but also existing code that interacts with anything the update changes, to ensure that integration is not introducing a vulnerability. This extends to non-blockchain code used to interact with the Validator, where applicable.
🔗 Updates MUST be tested on a staging environment that as closely as possible matches the proposed deployment environment before deployment as "production" on a live network
🔗 Node Operators MUST have a process to enable emergency rollback of upgrades
🔗 Node Operators SHOULD provide regular normal operational communication
This covers general information similar to financial reporting, major changes in staffing (overall size, key positions, strategic focus), and operator-specific information such as governance of onchain systems, key third-party relationships, software partnerships, participation in standards-setting, and the like.
The purpose is to provide confidence to stakeholders that the Node Operator is effectively managed, to enable them to understand the overall goals, and to show operational strengths, and plans to address perceived weaknesses and strategic threats.
🔗 The Node Operator MUST have documented Incident Response Plans corresponding to all risks identified in this specification
🔗 The Node Operator MUST have documented Disaster Recovery Plans corresponding to risks identified in this specification that lead to destruction of crucial data or loss of assets
🔗 Incident Response Plans and Disaster Recovery Plans MUST include revising the relevant plans whenever they are activated, based on lessons learned
This covers both responses to real incidents and Simulated activation, or Pre-mortems.
🔗 Node Operators MUST perform a simulated Incident and activation of the associated Incident Response Plan or Disaster Recovery Plans at least twice per year
🔗 Node Operators MUST document Incident Communication strategies or policies
This requirement includes internal and external communication, both during and after incidents.
🔗 Node Operators MUST verify that third parties providing services, or with whom the Node Operator contracts, are in compliance with relevant standards (including this one) and regulations
This includes areas such as the uptime guarantees of cloud providers and other core counterparties, response times and Service Level Agreements, security procedures, and the like as well as relevant regulatory compliance.
🔗 Service agreements MUST specify termination procedures and obligations
This document is an Editor's draft, for a proposed revision to the DUCK Knowledge Base (version 1).
Feedback is welcome, and is preferred as Issues, Pull requests and comments in this GitHub Repository. Please note the Conditions of Contributing.
The original content of this specification was developed as the DUCK Knowledge Base, and the current work is a direct evolution of that content.
In updating it, there are several changes being made. The key change is to move from a general explanation of risks and good practices to a specification that is well-suited to assessment of conformance.
Several somewhat cosmetic changes have been made. Most obviously, the name has been changed to ValOS - the Validator Operations Standard - and instead of a multi-page website it is available primarily as a single-page specification, in particular enabling easier use offline.
More importantly, there is a set of controls specific to ValOS, rather than only references to individual controls from other frameworks.
The update process aims to meet some general goals:
The approach to versions for this specification is to maintain a publicly visible "latest Editor's draft", representing the current state of what has been proposed and agreed as updates for a new version, and release versions, numbered 1, 2, 3 etc.
The "Editor's Draft" version may change frequently, for example weekly. It is primarily to serve the needs of the community involved or interested in the process of updating the specification. Part of that community is practitioners such as Node Operators themselves, developers and service providers, and assessors, who want to understand changes that they will need to make to their workflows in the short- to medium-term future.
We seek to provide transparency into proposed changes, and the process by which they are agreed or rejected, as well as the history of changes that have been made.
The release versions are intended to provide stable reference points, primarily for clarity in understanding the meaning of a specific assessment against a specific version.
The timing of new release versions seeks to balance keeping up with current best practice, and providing a stable target for learning and implementing. It is likely that a release cycle will be on the order of 6 to 18 months. The motivation for a new release can be the time elapsed since the last version, a major change to best practices or risks, or a combination of these factors, among others.
This section provides a summary of the Controls provided by this Specification.
| Control Group | Control(s) | Status | Comments | Risks | External Controls |
|---|---|---|---|---|---|
| Node Operators MUST document how their processes and tools serve their business goals | Node Operators MUST document how their processes and tools serve their business goals |
| |||
| Node Operators MUST review their dependencies on staff and external suppliers and how to replace key staff or suppliers every year | Node Operators MUST review their dependencies on staff and external suppliers and how to replace key staff or suppliers every year | ||||
| Node Operators MUST document their assessments of risks, and what risks they class as acceptable | Node Operators MUST document their assessments of risks, and what risks they class as acceptable | All risks |
| ||
| Node Operators MUST ensure that processes for risk mitigation are followed in practice | Node Operators MUST ensure that processes for risk mitigation are followed in practice | ||||
| Node Operators MUST document payment processes including currency and exchange details | Node Operators MUST document payment processes including currency and exchange details | ||||
| Node Operators MUST review relevant regulation and update processes for compliance as necessary at least quarterly | Node Operators MUST review relevant regulation and update processes for compliance as necessary at least quarterly | ||||
| Node Operators MUST know the identity of entities who are authorized to manage operations | Node Operators MUST know the identity of entities who are authorized to manage operations |
| |||
| Node Operators MUST implement documented procedures for evaluating and reviewing counterparty risks from vendors and partners | Node Operators MUST implement documented procedures for evaluating and reviewing counterparty risks from vendors and partners |
| |||
| Node Operators MUST ensure entities who are authorized to manage operations have and maintain the necessary knowledge to minimize risks to the Node Operator in the course of performing their work | Node Operators MUST ensure entities who are authorized to manage operations have and maintain the necessary knowledge to minimize risks to the Node Operator in the course of performing their work | ||||
| Node Operators MUST keep third-party software up to date | Node Operators MUST keep third-party software up to date | ||||
| Node Operators MUST have a persistent local anti-slashing database | Node Operators MUST have a persistent local anti-slashing database | ||||
| Node Operators MUST document signature requirements for high-value transactions, including the definitions used to identify such transactions |
| ||||
| Node Operators MUST deploy at least 2 distinct client applications for any level of the blockchain where at least 3 clients are available | Node Operators MUST deploy at least 2 distinct client applications for any level of the blockchain where at least 3 clients are available | ||||
| Devices that control critical functions MUST be dedicated to that purpose, and configured with only the necessary software for their intended purpose | Devices that control critical functions MUST be dedicated to that purpose, and configured with only the necessary software for their intended purpose | ||||
| Node Operators MUST implement processes to withdraw validators from a network in such a way that they are not penalised for disappearing | Node Operators MUST implement processes to withdraw validators from a network in such a way that they are not penalised for disappearing | ||||
| Node Operators MUST document configuration of software and hardware | Node Operators MUST document configuration of software and hardware | ||||
| Node Operators MUST implement appropriate key management procedures | Node Operators MUST implement appropriate key management procedures |
| |||
| Node Operators MUST document and follow information lifecycle processes for important operational information | Node Operators MUST document and follow information lifecycle processes for important operational information |
| |||
| Node Operators MUST implement backup procedures, at minimum daily, for important operational data |
| ||||
| Node Operators MUST record and maintain important operational information | Node Operators MUST record and maintain important operational information | ||||
| Node Operators MUST have a policy for data retention | Node Operators MUST have a policy for data retention | ||||
| All services MUST require appropriate authentication privileges | All services MUST require appropriate authentication privileges | ||||
| Networks MUST be segmented, to restrict access to systems that are identified as needing it |
|
| |||
| Entry to physical server locations MUST require authorization | Entry to physical server locations MUST require authorization | ||||
| Software MUST NOT run with, and a user MUST NOT have a higher level of privilege than necessary | Software MUST NOT run with, and a user MUST NOT have a higher level of privilege than necessary | ||||
| A review of Access Rights MUST take place regularly | A review of Access Rights MUST take place regularly | ||||
| All data in transit MUST be encrypted |
|
| |||
| Node Operators MUST log network traffic, and analyze the logs for anomalous behavior | Node Operators MUST log network traffic, and analyze the logs for anomalous behavior | ||||
| Any operation that requires privileged access MUST be logged |
|
| |||
| Every change in the status of people who have access to any function of the Node, or physical access to any hardware, MUST be logged | Every change in the status of people who have access to any function of the Node, or physical access to any hardware, MUST be logged | ||||
| Any event that results in slashing MUST be logged | Any event that results in slashing MUST be logged | ||||
| Logs MUST provide a sufficiently detailed view of hardware and network performance to enable upgrade needs to be forecast, and to alert if validators are operating with excess latency | Logs MUST provide a sufficiently detailed view of hardware and network performance to enable upgrade needs to be forecast, and to alert if validators are operating with excess latency | ||||
| Node Operators SHOULD have processes in place to manage environmental threats | Node Operators SHOULD have processes in place to manage environmental threats |
| |||
| Node Operators SHOULD implement failover validators in different physical locations | Node Operators SHOULD implement failover validators in different physical locations | ||||
| Node Operators SHOULD have processes in place to manage equipment lifecycles | Node Operators SHOULD have processes in place to manage equipment lifecycles |
| |||
| Code development MUST follow secure development processes to avoid introducing security risks | Code development MUST follow secure development processes to avoid introducing security risks |
| |||
| Node Operators MUST document procedures for updates to code | Node Operators MUST document procedures for updates to code | ||||
| Source code MUST be managed in a repository |
| ||||
| Updates to third-party software MUST be checked for vulnerabilities before deployment | Updates to third-party software MUST be checked for vulnerabilities before deployment | ||||
| Software update procedures MUST include an assessment and application of configuration settings | Software update procedures MUST include an assessment and application of configuration settings | ||||
| Code MUST verify that input is safe before operating on it |
| ||||
| Node Operators MUST have thorough test coverage of their software and operating procedures | Node Operators MUST have thorough test coverage of their software and operating procedures | All risks |
| ||
| Updates MUST include an audit of all code and user interactions they impact | Updates MUST include an audit of all code and user interactions they impact | ||||
| Updates MUST be tested on a staging environment that as closely as possible matches the proposed deployment environment before deployment as "production" on a live network | Updates MUST be tested on a staging environment that as closely as possible matches the proposed deployment environment before deployment as "production" on a live network |
| |||
| Node Operators MUST have a process to enable emergency rollback of upgrades | Node Operators MUST have a process to enable emergency rollback of upgrades | ||||
| Node Operators SHOULD provide regular normal operational communication | Node Operators SHOULD provide regular normal operational communication | ||||
| The Node Operator MUST have documented Incident Response Plans corresponding to all risks identified in this specification | The Node Operator MUST have documented Incident Response Plans corresponding to all risks identified in this specification | All risks | |||
| The Node Operator MUST have documented Disaster Recovery Plans corresponding to risks identified in this specification that lead to destruction of crucial data or loss of assets | The Node Operator MUST have documented Disaster Recovery Plans corresponding to risks identified in this specification that lead to destruction of crucial data or loss of assets |
| |||
| Incident Response Plans and Disaster Recovery Plans MUST include revising the relevant plans whenever they are activated, based on lessons learned | Incident Response Plans and Disaster Recovery Plans MUST include revising the relevant plans whenever they are activated, based on lessons learned | All risks |
| ||
| Node Operators MUST perform a simulated Incident and activation of the associated Incident Response Plan or Disaster Recovery Plans at least twice per year | Node Operators MUST perform a simulated Incident and activation of the associated Incident Response Plan or Disaster Recovery Plans at least twice per year | All risks | |||
| Node Operators MUST document Incident Communication strategies or policies | Node Operators MUST document Incident Communication strategies or policies | ||||
| Node Operators MUST verify that third parties providing services, or with whom the Node Operator contracts, are in compliance with relevant standards (including this one) and regulations | Node Operators MUST verify that third parties providing services, or with whom the Node Operator contracts, are in compliance with relevant standards (including this one) and regulations | ||||
| Service agreements MUST specify termination procedures and obligations | Service agreements MUST specify termination procedures and obligations |
Referenced in:
Referenced in:
Referenced in:
Referenced in:
Referenced in:
Referenced in:
Referenced in: